

배열
배열을 만들고 초기화 하는 방법
배열 선언
동일한 하나의 데이터형을 가진 연속된 원소들로 구성된다.
배열을 사용하려면 선언하여 컴파일러에게 알려야 한다.
- 선언 내용 : 그 배열이 가지는 원소의 개수(배열의 길이), 원소들의 데이터형
- float candy[365]; // 365개의 float형 값을 가지는 배열
- char code[12]; // 12개의 char형 값을 가지는 배열
- int states[50]; // 50개의 int형 값을 가지는 배열
- 배열 안에 있는 각 원소들은 인덱스라고 부르는 첨자 번호를 사용함으로써 개별적으로 접근할 수 있다.
- candy[0] : candy 배열의 첫 번째 원소
- candy[364] : candy 배열의 마지막 원소
초기화
배열은 콤마로 분리된 값들의 리스트를 중괄호로 감싸서 초기화한다. (값과 콤마 사이에 스페이스를 넣을 수 있다)
- int powers[8] = {1, 2, 4, 6, 8, 16, 32, 64};
- powers[0]에 값 1이 대입되고, 나머지 원소들도 차례로 값이 대입된다.
배열에 const 사용하기
배열을 선언하고 초기화할 때 const 키워드를 사용하면 배열을 읽기 전용으로 사용할 수 있다.
프로그램이 배열에서 값을 꺼내 오기는 하지만 배열에 새로운 값을 써 넣지 못하게 한다.
- const int days[MONTHS] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
- 이것은 프로그램이 배열에 있는 각 원소를 상수로 취급하게 만든다.
문제 01
/* 각 달의 날짜 수를 출력한다 */
#include <stdio.h>
#define MONTHS 12
int main(void)
{
int days[MONTHS] = {31,28,31,30,31,30,31,31,30,31,30,31};
int index;
for (index = 0; index < MONTHS; index++)
printf("%2d월 날짜 수 : %d일\n", index +1, days[index]);
printf("\n");
return 0;
}
#define MONTHS 12
- 배열 크기를 기호 상수 MONTHS를 사용하여 나타낸다.
- 만약 1년이 13개월로 바뀐다면, 해당하는 #define 지시문만 수정하면 되기 때문에 프로그램에서 배열 크기가 사용된 모든 곳을 찾아 고칠 필요가 없다.
문제 02
/* 초기화 시키지 않은 배열 */
#include <stdio.h>
#define SIZE 4
int main(void)
{
int no_data[SIZE]; // 초기화 시키지 않은 배열
int i;
printf("%2s%14s\n",
"i", "no_data[i]");
for (i = 0; i < SIZE; i++)
printf("%2d%14d\n", i, no_data[i]);
return 0;
}
int no_data[SIZE];
- 배열을 초기화하지 않으면 컴파일러는 우연히 그 메모리 위치에 놓여 있는 값들을 사용한다.
문제 03
/* 일부분만 초기화된 배열*/
#include <stdio.h>
#define SIZE 4
int main(void)
{
int some_data[SIZE] = {1492, 1066};
int i;
printf("%2s%14s\n",
"i", "some_data[i]");
for (i = 0; i < SIZE; i++)
printf("%2d%14d\n", i, some_data[i]);
return 0;
}
#define SIZE 4
…
int some_data[SIZE] = {1492, 1066};
- 초기값 리스트에 들어있는 항목들의 개수는 배열의 크기와 일치해야 한다.
- 초기값의 개수가 두 개 모자란 상태의 리스트를 가지고 초기화해도 컴파일러 오류는 발생하지 않지만,
컴파일러는 초기값 리스트에 있는 값들을 다 사용하고 나서, 나머지 원소들을 0으로 초기화한다.
- 초기값의 개수가 두 개 모자란 상태의 리스트를 가지고 초기화해도 컴파일러 오류는 발생하지 않지만,
- 사용자가 배열을 전혀 초기화하지 않으면 배열 원소들은 초기화하지 않은 보통의 변수들처럼 쓰레기 값들을 가지게 된다.
- 그러나 배열을 일부분만 초기화하면 나머지 원소들이 0으로 설정된다.
문제 04
/* 컴파일러가 원소 개수를 카운트 한다 */
#include <stdio.h>
int main(void)
{
const int days[] = {31,28,31,30,31,30,31,31,30,31};
int index;
for (index = 0; index < sizeof days / sizeof days[0]; index++)
printf("%2d월 날짜 수 : %d일\n", index +1,
days[index]);
printf("\n");
return 0;
}
const int days[] = {31,28,31,30,31,30,31,31,30,31};
- 빈 대괄호를 사용하여 배열을 초기화하면, 컴파일러는 초기값 리스트에 있는 항목들의 개수를 카운트하여 그것을 배열 크기로 가지는 배열을 만든다.
for (index = 0; index < sizeof days / sizeof days[0]; index++)
- sizeof 연산자는 객체 또는 데이터형(type)의 크기를 바이트 수를 리턴한다.
- sizeof days는 전체 배열의 바이트 수를 리턴하고, sizeof days[0]은 배열 원소 하나의 바이트 수를 리턴한다.
- 배열 전체 크기를 배열 원소 하나의 크기로 나누면, 그 배열에 몇 개의 원소가 있는지 알 수 있다.
const int days[] = {31,28,31,30,31,30,31,31,30,31};
- 실수로 값을 10개만 입력했지만 오류 없이 잘 작동된다.
- 배열 크기를 프로그램이 직접 알아내게 하는 것이 배열의 끝을 지나쳐서 출력하는 사태를 예방한다는 점은 좋지만,
원소의 개수가 틀렸더라도 컴파일러가 에러를 알려주지 않으니 내가 알아서 잘해야한다는 말도 된다.
문제 05
int arr[6] = {[5] = 212};
- 이 방식으로 최소한 하나의 원소를 초기화하면, 초기화하지 않는 나머지 원소들은 0으로 설정된다.
/* 지정 초기화자를 사용한다 */
#include <stdio.h>
#define MONTHS 12
int main(void)
{
int days[MONTHS] = {31,28, [4] = 31,30,31, [1] = 29};
int i;
for (i = 0; i < MONTHS; i++)
printf("%2d %d\n", i + 1, days[i]);
return 0;
}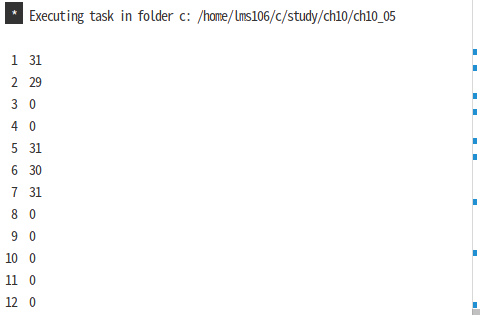
int days[MONTHS] = {31,28, [4] = 31,30,31, [1] = 29};
- 초기화 리스트에서 대괄호 안에 인덱스를 사용하여 특정 원소를 초기화하도록 지정할 수 있다.
- [4] = 31, 30, 31
- 하나의 지정 초기화자 뒤에 여러 개의 값이 붙으면 그 값들은 이어지는 다음 원소들을 초기화하는 데 사용한다.
day[4]가 31로 초기화 되고, day[5]와 [6]이 0과 31로 각각 초기화된다.
- 하나의 지정 초기화자 뒤에 여러 개의 값이 붙으면 그 값들은 이어지는 다음 원소들을 초기화하는 데 사용한다.
- [1] = 29
- 특정 원소가 어떤 값으로 한 번 이상 초기화되면, 마지막에 행해진 초기화가 유효하다.
- 처음에 days[1]이 28로 초기화 되지만, 나중의 [1] = 29에 의해 번복된다.
- [4] = 31, 30, 31
배열의 인덱스
배열에 값 대입하기
배열을 선언한 후에는 하나의 배열 인덱스를 사용하여 배열 원소들에 값들을 대입할 수 있다.
* 허용되지 않는 대입 형식
- C는 하나의 배열을 다른 배열에 통째로 대입하는 것을 허용하지 않는다.
- 초기화할 때 외에는 리스트에 값들을 나열하고 중괄호로 묶는 형식을 사용할 수 없다.
/* 유효하지 않은(invalid) 배열에 값 대입하기 */
#define SIZE 5
int main(void)
{
int oxen[SIZE] = {5, 3, 2, 8}; // 허용 된다. {5, 3, 2, 8, 0}
int yaks[SIZE];
yaks = oxen; // 허용되지 않는다.
yaks[SIZE] = oxen[SIZE]; // 유효하지 않다.
yaks[SIZE] = {5, 3, 2, 8}; // 동작하지 않는다.
}- oxen의 마지막 원소가 oxen[SIZE-1]이므로 oxen[SIZE]와 yaks[SIZE]는 두 배열 밖에 있는 데이터를 참조한다.
배열의 범위
컴파일러가 유효한 범위 내에 있는 배열 인덱스를 사용하고 있는지 확인해주지 않기 때문에, 배열 인덱스의 값이 그 배열에 대해 유효한지 확인하는 것은 중요하다.
컴파일러 인덱스들이 유효한지 검사해주지 않아서 잘못된 인덱스를 사용했을 때 어떤 결과가 나올지 정의되지 않는다. 이것은 프로그램을 실행했을 때 제대로 동작하는 것처럼 보일 수도 있고, 엉뚱하게 동작할 수도 있고, 아예 먹통이 될 수도 있다.
문제 06
/* 배열의 범위를 벗어난다 */
#include <stdio.h>
#define SIZE 4
int main(void)
{
int value1 = 44;
int arr[SIZE];
int value2 = 88;
int i;
printf("value1 = %d, value2 = %d\n", value1, value2);
for (i = -1; i <= SIZE; i++)
arr[i] = 2 * i + 1;
for (i = -1; i < 7; i++)
printf("%2d %d\n", i , arr[i]);
printf("value1 = %d, value2 = %d\n", value1, value2);
printf("arr[-1]의 주소 : %p\n", &arr[-1]);
printf("arr[4]의 주소 : %p\n", &arr[4]);
printf("value1의 주소 : %p\n", &value1);
printf("value2의 주소 : %p\n", &value2);
printf("\n");
return 0;
}
배열 크기 지정하기
#define SIZE 4
int main(void)
{
int arr[SIZE]; // 기호 정수 상수
double lots[144]; // 리터럴 정수 상수
int n = 5;
int m = 8;
float a1[5]; // 가능
float a2[5*2 +1]; // 가능
float a3[sizeof(int) +1]; // 가능
float a4[-4]; // 불가능 : 배열 크기는 0보다 커야 한다
float a5[0]; // 불가능 : 배열 크기는 0보다 커야 한다
float a6[2.5]; // 불가능 : 배열 크기는 정수여야 한다
float a7[(int)2.5]; // 가능
/* 가변길이배열 VLA */
float a8[n]; // 가능 C99 이전에는 허용되지 않았다
float a9[m]; // 가능 C99 이전에는 허용되지 않았다
}
다차원 배열
2차원 배열의 사용
기상청에서 지난 5년 간의 월별 강우량을 분석하고자 할 때, 데이터를 어떻게 표현할 것인지 결정해야 한다.
한 가지 가능한 선택은 각 데이터 항목마다 하나씩 총 60개의 변수를 사용하는 것이다. → 답답함
60개의 원소를 가지는 배열을 사용하면 좀 나아지겠지만, 데이터를 연도별로 분리할 수 있다면 더 좋을 것이다.
각각 12개의 원소를 가지는, 5개의 배열을 사용할 수 있을 것이다. 그런데 5년이 아니라 50년 간의 강우량을 분석해야 한다면 이 방법도 마찬가지로 다루기 힘들고 불편할 것이다.
좀 더 나은 방법은 '배열의 배열'을 사용하는 것이다.
주 배열은 각 연도에 해당하는 5개의 원소를 가진다. 이 원소들은 다시 1년의 각 달에 해당하는 12개의 원소를 가지는 배열이다.
float rain[5][12]; // float형 원소 12개인 배열이, 5개의 원소인 배열 → 5행 12열의 2차원 배열로 시각화 할 수 있다.

- 내부적으로 첫 번째 12원소 배열부터 시작하여, 그 다음에 두 번째 12원소 배열이 오고, 차례대로 다섯 번째 12원소 배열까지 연속적으로 저장된다.
문제 07
/*
강우량 데이터로부터 각 해의 총 강우량과
몇 년에 걸쳐 계산한 연평균 강우량,
각 달의 월평균 강우량을 구한다
*/
#include <stdio.h>
#define MONTHS 12 // 1월 ~ 12월
#define YEARS 5 // 데이터를 수집한 햇수
int main(void)
{
// 2010 - 2014 강우량 데이터 초기화
const float rain[YEARS][MONTHS] =
{
{4.3,4.3,4.3,3.0,2.0,1.2,0.2,0.2,0.4,2.4,3.5,6.6},
{8.5,8.2,1.2,1.6,2.4,0.0,5.2,0.9,0.3,0.9,1.4,7.3},
{9.1,8.5,6.7,4.3,2.1,0.8,0.2,0.2,1.1,2.3,6.1,8.4},
{7.2,9.9,8.4,3.3,1.2,0.8,0.4,0.0,0.6,1.7,4.3,6.2},
{7.6,5.6,3.8,2.8,3.8,0.2,0.0,0.0,0.0,1.3,2.6,5.2}
};
int year, month;
float subtot, total;
printf(" 년도 강우량(인치)\n");
/* 각 해에 대해 12달치 강우량을 더한다 */
for (year = 0, total = 0; year < YEARS; year++)
{
for (month = 0, subtot = 0; month < MONTHS; month++)
subtot += rain[year][month];
printf("%5d %15.1f\n", 2010 + year, subtot);
total += subtot; // 여러 해에 걸친 총 강우량을 구한다.
}
printf("\n연평균 강우량은 %.1f인치 입니다.\n\n", total/YEARS);
printf("월평균 강우량은 다음과 같습니다.\n\n");
printf(" Jan Feb Mar Apr May Jun Jul Aug Sep Oct ");
printf(" Nov Dec\n");
for (month = 0; month < MONTHS; month++)
{ // 각 해에 대해 12달치 강우량을 더한다.
for (year = 0, subtot =0; year < YEARS; year++)
subtot += rain[year][month];
printf("%4.1f ", subtot/YEARS);
}
printf("\n");
return 0;
}
for (year = 0, total = 0; year < YEARS; year++) .. ─ ①
{
for (month = 0, subtot = 0; month < MONTHS; month++) ─ ②
…
}
- 주어진 한 해의 총 강우량을 구하려면,
- ① year을 일정하게 유지하면
- ② month를 전 범위에 걸쳐서 변화시켜야 한다.
- ① year의 다음 값을 가지고 그 과정을 반복한다.
for (month = 0; month < MONTHS; month++) ─ ①
{
for (year = 0, subtot =0; year < YEARS; year++) ─ ②
…
}
- 각 달에 대해 5년치 강우량을 구하려면,
- ① month를 일정하게 유지하면서
- ② year를 전 범위에 걸쳐서 변화시켜야 한다.
- ① month의 다음 값을 가지고 그 과정을 반복한다.
2차원 배열을 처리하는 데에는 이와 같이 중첩 루프 구조가 자연스럽다. 하나의 루프가 첫 번째 인덱스를 처리하고, 다른 하나의 루프가 두 번째 인덱스를 처리한다.
2차원 배열의 초기화
2차원 배열의 초기화는 1차원 배열의 초기화 테크닉을 이용한다.
/* 1차원 배열의 초기화 */
sometype ar1[5] = {val1, val2, val3, val4, val5};/* 2차원 배열의 초기화 */
const float rain[YEARS][MONTHS] =
{
{4.3,4.3,4.3,3.0,2.0,1.2,0.2,0.2,0.4,2.4,3.5,6.6},
{8.5,8.2,1.2,1.6,2.4,0.0,5.2,0.9,0.3,0.9,1.4,7.3},
{9.1,8.5,6.7,4.3,2.1,0.8,0.2,0.2,1.1,2.3,6.1,8.4},
{7.2,9.9,8.4,3.3,1.2,0.8,0.4,0.0,0.6,1.7,4.3,6.2},
{7.6,5.6,3.8,2.8,3.8,0.2,0.0,0.0,0.0,1.3,2.6,5.2}
};- 이 초기화는, 내부 중괄호로 감싼 값들의 리스트 5개를 또 다른 하나의 외부 중괄호로 감싸고 있다.
- 첫 번째 내부 중괄호에 있는 데이터는 배열의 첫 번째 행에 대입된다.
- 두 번째 내부 중괄호에 있는 데이터는 배열의 두 번째 행에 대입된다.
- 나머지 데이터들도 차례로 대입된다.
- 내부 중괄호들을 생략하고 외부 중괄호만 사용할 수도 있다. 항목들의 개수를 정확하게만 유지한다면, 효과는 동일하다.
- 그러나 항목들의 개수가 부족하면, 데이터가 다 떨어질 때까지 행에서 행으로 이어지면서 배열이 채워진다.
- 그러고 나서 값을 배정받지 못한 나머지 원소들은 0으로 초기화된다.

포인터와 배열
배열의 이름
배열의 이름은 첫 번째 원소의 주소다.
flizny == &flizny[0]
배열과 포인터의 덧셈
일반적으로 우리가 사용하는 시스템은 바이트 단위로 주소가 매겨진다.
short형은 2바이트를 사용하고, double형은 8바이트를 사용한다. 그러므로 포인터에 1을 더한다고 말할 때, C는 하나의 기억 단위를 더한다.
배열의 경우에 이것은, 주소가 다음 바이트가 아니라 다음 원소(element)의 주소로 증가한다는 것을 의미한다.
이것이 포인터가 가리키는 객체의 종류를 선언해야 하는 이유이다. 그 객체를 저장하는 데 얼마나 많은 바이트가 필요한지 컴퓨터가 알아야 하기 때문에, 주소만으로는 충분하지 않다.

포인터 정의
int형을 가리키는 포인터와 float형을 가리키는 포인터 또는 다른 어떤 데이터 객체를 가리키는 포인터가 의미하는 것을 명확하게 정의할 수 있다.
1. 포인터의 값은 그것이 가리키는 객체의 주소이다. 내부적으로 주소를 나타내는 방식은 하드웨어마다 다르다.
여기서 double형 변수와 같이 큰 객체의 주소는 일반적으로 그 객체의 첫 번째 바이트의 주소다.
2. 포인터에 * 연산자를 적용하면 그 포인터가 가리키는 객체에 저장되어 있는 값을 얻는다.
3. 포인터에 1을 더하면, 그 포인터가 가리키는 객체의 바이트 수 크기만큼 포인터 값이 증가한다.
배열과 포인터의 관계
dates + 2 == &dates[2] // 주소가 같다
*(date + 2) == dates[2] // 값이 같다
이러한 관계는 배열과 포인터가 밀접한 연관이 있음을 보여준다. 이들은 배열의 개별적인 원소에 접근하고, 그 값을 얻는 데 포인터를 사용할 수 있다는 것을 의미한다.
본질적으로 이것은 같은 것을 나타내는 두 가지 다른 표기이다. 실제로 C언어 표준은, 배열 표기를 포인터로 서술한다. 즉, ar[n]이 *(ar+n)을 의미하도록 정의한다.
→ *(ar+n) : ① 메모리 위치 ar로 가라 ② n개의 기억 단위 만큼 이동해라 ③ 거기에 있는 값을 꺼내라
*(dates + 2) // dates의 세 번째 원소 값
*dates + 2 // dates의 첫 번째 원소의 값에 2를 더한다
간접 연산자 *가 +보다 우선 순위가 높기 때문에 둘은 다르다.
문제 08
/* 포인터 덧셈 */
#include <stdio.h>
#define SIZE 4
int main(void)
{
short dates [SIZE];
short * pti;
short index;
double bills[SIZE];
double * ptf;
pti = dates; // 배열의 주소를 포인터에 대입한다.
ptf = bills;
printf("%22s %14s\n", "short", "double");
for (index = 0; index < SIZE; index ++)
printf("포인터 + %d: %10p %10p\n",
index, pti + index, ptf + index);
return 0;
}
문제 09
/* 포인터 표기를 사용한다 */
#include <stdio.h>
#define MONTHS 12
int main(void)
{
int days[MONTHS] = {31,28,31,30,31,30,31,31,30,31,30,31};
int index;
for (index = 0; index < MONTHS; index++)
printf("%2d월 날짜 수 : %d일\n", index +1,
*(days + index)); // days[index]와 같다
return 0;
}
for (index = 0; index < MONTHS; index++)
printf("%2d월 날짜 수 : %d일\n", index +1,
*(days + index));
- 루프는 배열의 각 원소에 차례로 접근하여 그것의 내용을 출력한다.
- days는 그 배열의 첫 번째 원소의 주소이다.
- days+index는 원소 days[index]의 주소다.
- *(days+index)는 그 원소의 값, 즉 days[index]다.
함수
함수와 배열과 포인터
배열을 조작하는 함수
어떤 배열의 원소들의 합을 리턴하는 함수를 작성해야 한다고 가정할 때, marbles가 int형의 원소들을 가지는 배열이라고 가정한다.
total = sum(marbles); // 가능한 함수 호출의 한 예
배열의 이름은 첫 번째 원소의 주소라는 사실을 기억하고, int형인 주소의 실전달인자 marbles는 int형을 가리키는 포인터인 형식매개변수에 대입되어야 한다.
int sum(int * ar); // 대응하는 함수 프로토타입
sum()은 전달인자로부터 배열의 첫 번째 원소의 주소를 얻을 수 있고, 그 위치에서 하나의 int형을 찾을 수 있다.
이 정보는 배열에 있는 원소의 개수에 대해서는 아무것도 알려주지 않는다. 그렇기 때문에 대응하는 함수 정의를 작성할 수 있는 방법은 두 가지가 있다.
방법1. 고정된 배열 크기를 함수 안에 코딩하는 것
int sum(int *ar)
{
int i;
int total = 0;
for (i=0; i<10; i++) // 원소가 10개라고 가정한다
total += ar[i] // ar[i]는 *(ar+i)와 같다
return total;
}- 여기서 우리는, 배열 이름에 포인터 표기를 사용할 수 있는 것처럼, 포인터에 배열 표기를 사용할 수 있다는 사실을 이용한다.
- total은 배열 원소들의 누계가 된다.
- 이 함수 정의는 제한적이다. 이 함수는 10개의 원소를 가지는 배열에 대해서만 동작한다.
방법2. 배열 크기를 두 번째 전달인자로 함수에 전달하는 것이다.
int sum(int *ar, int n)
{
int i;
int total = 0;
for (i=0; i<n; i++) // n개의 원소를 사용한다
total += ar[i] // ar[i]는 *(ar+i)와 같다
return total;
}- 첫 번째 형식매개변수는 배열을 찾을 장소와 배열에 있는 데이터형을 함수에게 알린다.
- 두 번째 형식매개변수는 배열에 몇 개의 원소가 있는지 함수에게 알린다.
- 함수 프로토타입이나 함수의 정의 머리에서만, int * ar를 int ar[]로 대체할 수 있다.
int sum(int ar[], int n);- int * ar 형식은 언제나 ar이 int형을가리키는 포인터형이라는 것을 뜻한다.
- int ar[] 형식은
- 형식매개변수의 선언에 사용될 때만 ar이 int형을 가리키는 포인터라는 것을 뜻한다.
- ar이 int형을 가리킬 뿐만 아니라, 그것이 배열의 한 원소인 int형을 가리킨다는 사실을 알려준다.
배열 매개변수의 선언
배열 이름은 첫 번째 원소의 주소이기 때문에, 배열 이름을 실전달인자로 사용하려면 대응하는 형식매개변수가 포인터가 되어야 한다. C는 이 상황에서만 int ar[]를 int *ar와 같은 의미(ar이 int형을 가리키는 포인터형)라고 해석한다.
프로토타입에서는 이름을 생략할 수 있기 때문에 다음 네 개의 프로토타입은 모두 동등하다.
int sum(int *ar, int n);
int sum(int *, int);
int sum(int ar[], int n);
int sum(int [], int);
함수 정의에서는 이름을 생략할 수 없다. 그래서 함수 정의에서는 다음 두 가지 형식만 동등하다.
int sum(int *ar, int n)
{
// 여기에 코드를 넣는다
}
int sum(int ar[], int n)
{
// 여기에 코드를 넣는다
}
문제 10
- 최초 배열의 크기와 그 배열을 나타내는 함수 매개변수의 크기를 출력한다.
/* 배열의 원소들의 합을 구한다 */
#include <stdio.h>
#define SIZE 10
int sum(int ar[], int n);
int main(void)
{
int marbles[SIZE] = {20,10,5,39,4,16,19,26,31,20};
long answer;
answer = sum(marbles, SIZE);
printf("구슬의 전체 개수는 %ld개 입니다.\n", answer);
printf("marbles의 크기는 %zd 바이트 입니다.\n",
sizeof marbles);
return 0;
}
int sum(int ar[], int n) // 배열 크기는 얼마일까?
{
int i;
int total = 0;
for( i = 0; i < n; i++)
total += ar[i];
printf("ar의 크기는 %zd 바이트 입니다.\n",sizeof ar);
return total;
}
- " marbles의 크기는 40 바이트 입니다. "
- marbles가 4바이트인 int형 원소를 10개 가지기 때문에 크기가 총 40바이트라는 것은 이치에 맞다.
- " ar의 크기는 8 바이트 입니다."
- ar이 배열 그 자체가 아니라 marbles의 첫 번째 원소를 가리키는 포인터 이기 때문에 고작 8바이트가 맞다.
- 출력에 사용한 시스템은 8바이트 주소를 사용하므로, 포인터 변수의 크기가 8바이트이다. (시스템바이시스템)
- 정리하면, marbles는 배열이다. ar은 marbles의 첫 번째 원소를 가리키는 포인터다.
- 배열과 포인터의 이러한 관계 때문에, 배열 표기에 포인터 ar을 사용할 수 있다.
포인터 매개변수의 사용
배열을 조작하는 함수는 어디에서 시작하고 끝나는지를 알아야 한다.
sum() 함수는 배열의 시작 위치를 나타내기 위해 하나의 포인터 매개변수를 사용하고, 몇 개의 원소를 처리할 것인지를 나타내기 위해 하나의 정수 매개변수를 사용한다. (포인터 매개변수는 배열의 원소 데이터형도 알려준다.)
그러나 이것이 함수에 필요한 정보를 알리는 유일한 방법은 아니다. 함수에 배열을 알리는 또 다른 방법은 두 개의 포인터를 전달하는 것이다. 첫 번째 포인터는 배열의 시작 위치를, 두 번째 포인터는 배열이 끝나는 위치를 알려준다.
문제 11
- 두 개의 포인터를 전달하는 방식을 사용한다.
- 포인터 매개변수가 변수라는 사실을 이용한다. 즉, 배열에서 어느 원소에 접근할 것인지를 나타내기 위해 인덱스를 사용하는 대신에 배열의 원소들을 차례대로 가리킬 수 있도록 함수가 포인터 자체의 값을 변경할 수 있다.
/* 배열의 원소들의 합을 구한다 */
#include <stdio.h>
#define SIZE 10
int sump(int * start, int * end);
int main(void)
{
int marbles[SIZE] = {20,10,5,39,4,16,19,26,31,20};
long answer;
answer = sump(marbles, marbles + SIZE);
printf("구슬의 전체 개수는 %ld개입니다.\n", answer);
printf("\n");
return 0;
}
/* 포인터 계산을 사용한다 */
int sump(int * start, int * end)
{
int total = 0;
while (start < end)
{
total += *start; // total에 값을 더한다
start++; // 포인터를 증가시켜 다음 원소를 가리킨다
}
return total;
}
total += *start;
- 포인터 start는 marbles의 첫 번째 원소를 가리키면서 시작한다.
- 첫 번재 원소의 값(20)을 total에 더한다.
start++;
- 포인터 변수 start를 증가시켜 배열에 있는 다음 원소를 가리킨다.
- start가 int형을 가리키기 때문에 C는 start의 값을 int형의 크기만큼 증가시킨다.
int sump(int * start, int * end)
{
int total = 0;
while (start < end)
- sump() 함수는 원소들의 개수를 두 번째 전달 인자로 사용한다.
- 루프는 그 값을 루프 검사에 사용한다
- 조건 표현식이 부등성을 검사하기 때문에, 마지막으로 처리되는 원소는 end-1에 있는 원소이다.
while (start < end)
{
total += *start;
start++;
}
- 루프의 몸체를 다음과 같이 한 라인으로 줄일 수 있다.
total += *start++; - 단항 연산자 *와 ++는 우선순위는 같지만 오른쪽에서 왼쪽으로 결합한다.
- 이것은 ++가 *start가 아니라 start에 적용된다는 것을 의미한다.
- 즉, 포인터가 기리키는 값이 아니라 포인터 자체가 증가된다.
- 후위 모드의 사용은 포인터가 가리키는 값이 total에 더해진 후에 포인터가 증가된다는 것을 의미한다.
- 프로그램이 ++start 형식을 사용한다면, 포인터가 먼저 증가되고 증가된 포인터가 가리키는 값이 total에 더해질 것이다.
- 프로그램이 (*start)++ 형식을 사용한다면, start의 값을 total에 더하고 나서 포인터가 아니라 그 값을 증가시킬 것이다.
- 이것은 포인터가 계속해서 같은 원소를 가리키게 하고 그 원소에 (1이 증가된) 새로운 값을 대입할 것이다.
- *start++ 표기가 일반적으로 사용되지만, 분명하게 하려면 *(start++)를 사용해야 한다.
문제 12
/* 포인터 연산에서의 우선순위 */
#include <stdio.h>
int data[2] = {100, 200};
int moredata[2] = {300, 400};
int main(void)
{
int * p1, * p2, * p3;
p1 = p2 = data;
p3 = moredata;
printf(" *p1 = %d, *p2 = %d, *p3 = %d\n",
*p1 , *p2 , *p3);
printf("*p1++ = %d, *++p2 = %d, (*p3)++ = %d\n",
*p1++ , *++p2 , (*p3)++);
printf(" *p1 = %d, *p2 = %d, *p3 = %d\n",
*p1 , *p2 , *p3);
return 0;
}
- 여기서 (*p3)++ 연산만이 배열의 값을 유일하게 변경시켰다.
- 다른 두 연산은 p1과 p2를 배열의 다음 원소를 가리키도록 전진시켰다.
C언어에서 배열 표기 ar[i]와 포인터 표기 *(ar+i)는 같은 의미를 가진다.
ar이 배열 이름이면 둘 다 동작한다.
ar이 포인터 변수일 때에도 둘 다 동작한다.
ar++와 같은 연산은 ar이 포인터 변수일 때만 동작한다.
특별히 증가 연산자와 함께 사용할 때, 포인터 표기는 기계어 코드에 가깝고, 일부 컴파일러들은 좀 더 효율적인 코드를 생성한다. 그러나 정확성과 명확성은 프로그래머의 생명이며, 코드 최적화는 컴파일러의 몫이다.
포인터
포인터 연산
대입하기
포인터에 주소를 대입할 수 있다.
예를 들면 대입값은 주소 연산자(&) 뒤에 오는 변수, 즉 배열 이름이나 다른 제2의 포인터가 될 수 있다.
- <문제 13에서>
- 포인터 변수 ptr1에 배열 urn의 시작 주소가 대입된다.
- 포인터 변수 ptr2에 세 번째이자 마지막 원소인 urn[2]의 주소가 대입된다.
- 그 주소는 포인터형과 일치해야 한다. 즉, 무분별한 데이터형 캐스트를 사용하지 않고서는 double형 값의 주소를 int형을 가리키는 포인터에 대입할 수 없다.
값 구하기(내용 참조/역참조)
* 연산자는 그것이 참조하는 주소에 저장되어 있는 값을 구한다.
- <문제 13에서>
- 처음에 *ptr1은 메모리 셀 주소에 저장되어 있는 값 100이다.
포인터 주소 얻기
모든 변수들과 마찬가지로, 포인터 변수도 하나의 주소와 하나의 값을 가진다.
& 연산자는 포인터 자체가 어디에 저장되어 있는지 알려준다.
- <문제 13에서>
- ptr1은 메모리 위치 0x????????????에 저장되어 있다.
- 이 메모리 셀의 내용은 urn의 주소인 0x!!!!!!!!!!!!이다.
- 따라서 &prt1은 pt1을 가리키고, 결과적으로 포인터는 urn[0]을 가리킨다.
포인터에 정수 더하기
포인터에 정수를 더하거나, 정수에 포인터를 더하기 위해 + 연산자를 사용할수 있다.
어느 경우에나 정수는 포인터가 가리키는 데이터형의 바이트 수만큼 곱해진다.
그 결과가 최초의 주소에 더해진다.
- <문제 13에서>
- ptr1 + 4를 &urn[4]와 같게 만든다.
- 그 배열의 마지막 원소 바로 다음 주소가 유효하다고 보장하는 것을 제외하고, 덧셈의 결과가 최초의 포인터가 가리키는 배열의 범위를 벗어나는지는 정의되지 않는다.
포인터 증가시키기
배열의 한 원소를 가리키는 포인터를 증가시키면, 그 포인터가 배열의 다음 원소를 가리키게 된다.
- <문제 13에서>
- ptr1++는 ptr1의 값을 4(int형은 4바이트)만큼 증가시킨다. 이것은 ptr1이 urn[1]을 가리키게 만든다.
- 이제 ptr1은 배열의 다음 원소의 주소 값을 가진다.
- 그리고 *ptr1은 값 200(urn[1]의 값)을 가진다.
- ptr1 자체의 주소는 그대로 유지된다. 변수는 자신의 값을 변경할 뿐 자신이 이동하지는 않는다.
포인터에서 정수 빼기
포인터에서 정수를 빼기 위해 - 연산자를 사용할 수 있다.
포인터는 첫 번째 피연산자이고 정수값은 두 번째 피연산자가 되어야 한다.
정수는 포인터가 가리키는 데이터형의 바이트 수만큼 곱해진다.
그러고 나서 최초의 주소에서그 결과가 감해진다.
- <문제 13에서>
- ptr1++는 ptr1의 값을 4(int형은 4바이트)만큼 증가시킨다. 이것은 ptr1이 urn[1]을 가리키게 만든다.
- 이제 ptr3-2를 &urn[2]와 같게 만든다. // ptr3이 &urn[4]를 가리키기 때문에
- 그 배열의 마지막 원소 바로 다음의 주소가 유효하다고 보장하는 것을 제외하고, 뺄셈의 결과가 최초의 포인터가 가리키는 배열의 범위를 벗어나는지는 정의되지 않는다.
포인터 감소시키기
포인터를 감소시킬 수도 있다.
- <문제 13에서>
- ptr2를 감소시키면, 배열의 세 번째 원소가 아니라 두 번째 원소를 가리키게 된다.
증가 연산자와감소 연산자의 전위 모드와 후위 모드를 둘 다 사용할 수 있다.

- <문제 13에서>
- 최초의 값으로 복원되기 전에, 두 포인터 ptr1과 ptr2가 둘 다 동일한 원소 urn[1]을 가리킨다.
포인터 사이의 차 구하기
두 포인터 사이의 차를 구할 수 있다.
일반적으로, 같은 배열에 있는 원소들이 서로 얼마나 떨어져 있는지 알아내기 위해 같은 배열의 두 원소를 가리키는 포인터들에 이 연산을 수행한다.
그 결과는 데이터형 크기와 같은 단위로 구해진다.
- <문제 13에서>
- ptr2 - ptr1은 값 2를 가진다. 이것은 두 포인터가 2바이트가 아니라 2개의 int형 크기만큼 떨어져 있는 객체들을 가리킨다는 것을 의미한다. (배열의 마지막 원소 바로 다음 위치까지 포함하여)
- 두 포인터가 같은 배열의 원소들을 가리키는 한, C는 포인터 사이의 차를 구하는 게 유효한 연산이라고 보장한다.
- 서로 다른 두 배열을 가리키는포인터들에 이 연산을 수행하면 값을 얻을수도 있고 런타임 에러가 발생할 수도 있다.
포인터 비교하기
두 포인터가 같은 데이터형을 가리키는 경우, 두 포인터의 값을 비교하기 위해 관계 연산자를 사용할 수 있다.
포인터 증감 시 주의사항
포인터가 여전히 배열 원소를 가리키는지 컴퓨터는 검사하지 않는다.
C는 어떤 배열이 주어졌을 때, 배열의 원소를 가리키는 포인터와 마지막 원소 바로 다음의 위치를 가리키는 포인터가 유효한 포인터라고 보장한다.
마지막 원소 바로 다음 위치를 가리키는 포인터가 유효하다고 보장은 하지만, 그 포인터가 가리키는 내용을 참조할 수 있다고 보장하지 않는다.
문제 13
/* 포인터 연산 */
#include <stdio.h>
int main(void)
{
int urn[5] = {100,200,300,400,500};
int * ptr1, * ptr2, *ptr3;
ptr1 = urn; // 포인터에 주소를 대입한다
ptr2 = &urn[2]; // 포인터에 주소를 대입한다
/* 역참조된 포인터를 참조하여 포인터의 주소를 얻는다 */
printf("포인터의 값, 역참조된 포인터가 가리키는 값, 포인터의 주소 : \n");
printf("ptr1 = %p, *ptr1 =%d, &ptr1 = %p\n",
ptr1, *ptr1, &ptr1);
/* 포인터 덧셈 */
ptr3 = ptr1 + 4;
printf("\n포인터에 정수를 더한다: \n");
printf("ptr1 + 4 = %p, *(ptr4 + 3) = %d\n",
ptr1 + 4, *(ptr1 + 3));
ptr1++; // 포인터를 증가시킨다
printf("\nptr1++을 수행한 후의 값 : \n");
printf("ptr1 = %p, *ptr1 =%d, &ptr1 = %p\n",
ptr1, *ptr1, &ptr1);
ptr2--; // 포인터를 감소시킨다
printf("\nptr2를 수행한 후의 값 : \n");
printf("ptr2 = %p, *ptr2 = %d, &ptr2 = %p\n",
ptr2, *ptr2, &ptr2);
--ptr1; // 최초의 값으로 복원한다
++ptr2; // 최초의 값으로 복원한다
printf("\n두 포인터를 최초의 값으로 복원한다 : \n");
printf("ptr1 = %p, ptr2 = %p\n", ptr1, ptr2);
/* 포인터에서 다른 포인터를 뺀다 */
printf("\n포인터에서 다른 포인터를 뺀다 : \n");
printf("ptr2 = %p, ptr1 = %p, ptr2 - ptr1 = %td\n",
ptr2, ptr1, ptr2 - ptr1);
/* 포인터에서 정수를 뺀다 */
printf("\n포인터에서 정수를 뺀다 : \n");
printf("ptr3 = %p, ptr3 - 2 = %p\n",
ptr3, ptr3 - 2);
return 0;
}
문제 14
/* 배열 처리 함수 */
#include <stdio.h>
#define SIZE 5
void show_array(const double ar[], int n);
void mult_array(double ar[], int n, double mult);
int main(void)
{
double dip[SIZE] = {20.0, 17.66, 8.2, 15.3, 22.22};
printf("원래의 dip 배열 : \n");
show_array(dip, SIZE);
mult_array(dip, SIZE, 2.5);
printf("mult_array() 호출 후의 dip 배열 : \n");
show_array(dip, SIZE);
return 0;
}
/* 배열의 내용을 표시한다 */
void show_array(const double ar[], int n)
{
int i;
for (i = 0; i < n; i++)
printf("%8.3f ", ar[i]);
putchar('\n');
}
/* 배열의 각 원소에 동일한 곱수를 곱한다 */
void mult_array(double ar[], int n, double mult)
{
int i;
for (i = 0; i < n; i++)
ar[i] *= mult;
}
문제 15
/* zippo 정보 */
#include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
printf(" zippo = %p, zippo + 1 = %p\n",
zippo, zippo + 1);
printf("zippo[0] = %p, zippo[0] + 1 = %p\n",
zippo[0], zippo[0] + 1);
printf(" *zippo = %p, *zippo + 1 = %p\n",
*zippo, *zippo + 1);
printf("zippo[0][0] = %d\n", zippo[0][0]);
printf(" *zippo[0] = %d\n", *zippo[0]);
printf(" **zippo = %d\n", **zippo);
printf(" zippo[2][1] = %d\n", zippo[2][1]);
printf("*(*(zippo+2) + 1) = %d\n", *(*(zippo+2) + 1));
return 0;
}
문제 16
/* 포인터 변수를 사용하는 zippo 정보 */
#include <stdio.h>
int main(void)
{
int zippo[4][2] = { {2,4}, {6,8}, {1,3}, {5, 7} };
int (*pz)[2];
pz = zippo;
printf(" pz = %p, pz + 1 = %p\n",
pz, pz + 1);
printf("pz[0] = %p, pz[0] + 1 = %p\n",
pz[0], pz[0] + 1);
printf(" *pz = %p, *pz + 1 = %p\n",
*pz, *pz + 1);
printf("pz[0][0] = %d\n", pz[0][0]);
printf(" *pz[0] = %d\n", *pz[0]);
printf(" **pz = %d\n", **pz);
printf(" pz[2][1] = %d\n", pz[2][1]);
printf("*(*(pz+2) + 1) = %d\n", *(*(pz+2) + 1));
return 0;
}
문제 17
/* 2차원 배열을 처리하는 함수 */
#include <stdio.h>
#define ROWS 3
#define COLS 4
void sum_rows(int ar[][COLS], int rows);
void sum_cols(int [][COLS], int ); // 이름들을 생략할 수 있다
int sum2d(int (*ar)[COLS], int rows); // 또 다른 프로토타입 신택스
int main(void)
{
int junk[ROWS][COLS] = {
{2,4,6,8},
{3,5,7,9},
{12,10,8,6}
};
sum_rows(junk, ROWS);
sum_cols(junk, ROWS);
printf("모든 원소들의 합계 = %d\n", sum2d(junk, ROWS));
printf("\n");
return 0;
}
void sum_rows(int ar[][COLS], int rows)
{
int r;
int c;
int tot;
for (r = 0; r < rows; r++)
{
tot = 0;
for (c = 0; c < COLS; c++)
tot += ar[r][c];
printf("%d행 : 소계 = %d\n", r, tot);
}
}
void sum_cols(int ar[][COLS], int rows)
{
int r;
int c;
int tot;
for (c = 0; c < COLS; c++)
{
tot = 0;
for (r = 0; r < rows; r++)
tot += ar[r][c];
printf("%d열 : 소계 = %d\n", c, tot);
}
}
int sum2d(int ar[][COLS], int rows)
{
int r;
int c;
int tot = 0;
for (r = 0; r < rows; r++)
for (c = 0; c < COLS; c++)
tot += ar[r][c];
return tot;
}
문제 18
//vararr2d.c -- functions using VLAs
#include <stdio.h>
#define ROWS 3
#define COLS 4
int sum2d(int rows, int cols, int ar[rows][cols]);
int main(void)
{
int i, j;
int rs = 3;
int cs = 10;
int junk[ROWS][COLS] = {
{2,4,6,8},
{3,5,7,9},
{12,10,8,6}
};
int morejunk[ROWS-1][COLS+2] = {
{20,30,40,50,60,70},
{5,6,7,8,9,10}
};
int varr[rs][cs]; // VLA
for (i = 0; i < rs; i++)
for (j = 0; j < cs; j++)
varr[i][j] = i * j + j;
printf("3x5 array\n");
printf("모든 원소들의 합계 = %d\n",
sum2d(ROWS, COLS, junk));
printf("2x6 array\n");
printf("모든 원소들의 합계 = %d\n",
sum2d(ROWS-1, COLS+2, morejunk));
printf("3x10 VLA\n");
printf("모든 원소들의 합계 = %d\n",
sum2d(rs, cs, varr));
printf("\n");
return 0;
}
// VLA 매개변수를 사용하는 함수
int sum2d(int rows, int cols, int ar[rows][cols])
{
int r;
int c;
int tot = 0;
for (r = 0; r < rows; r++)
for (c = 0; c < cols; c++)
tot += ar[r][c];
return tot;
}
문제 19
// 복합 리터럴을 사용한다
#include <stdio.h>
#define COLS 4
int sum2d(const int ar[][COLS], int rows);
int sum(const int ar[], int n);
int main(void)
{
int total1, total2, total3;
int * pt1;
int (*pt2)[COLS];
pt1 = (int [2]) {10, 20};
pt2 = (int [2][COLS]) { {1,2,3,-9}, {4,5,6,-8} };
total1 = sum(pt1, 2);
total2 = sum2d(pt2, 2);
total3 = sum((int []){4,4,4,5,5,5}, 6);
printf("total1 = %d\n", total1);
printf("total2 = %d\n", total2);
printf("total3 = %d\n", total3);
printf("\n");
return 0;
}
int sum(const int ar[], int n)
{
int i;
int total = 0;
for( i = 0; i < n; i++)
total += ar[i];
return total;
}
int sum2d(const int ar[][COLS], int rows)
{
int r;
int c;
int tot = 0;
for (r = 0; r < rows; r++)
for (c = 0; c < COLS; c++)
tot += ar[r][c];
return tot;
}
'C언어 > 스터디' 카테고리의 다른 글
| ch11 문자열과 문자열 함수 (0) | 2024.08.13 |
|---|---|
| ch11 문자열 p.551~ (0) | 2024.08.12 |
| ch09 함수 (0) | 2024.08.10 |
| ch7 제어문_분기와 점프 (0) | 2024.08.09 |
| ch6 제어문_루프 문제 (0) | 2024.08.08 |